

Why Coinbase and Pinterest Chose StarRocks: Lakehouse-Native Design and Fast Joins at Terabyte Scale


Why is StarRocks gaining popularity among data engineers who need fast analytics on large-scale data? To find out, I did a deep dive on the companies actually using StarRocks in production, interviewing engineers and studying technical case studies from Coinbase, Pinterest, Fresha, Grab, TRM Labs, and Shopee. They all share a similar pattern: customer-facing analytics on Snowflake got too slow, and they needed sub-second query responses without heavy pre-denormalization in Flink or Spark.
Two questions interested me most. Why do joins seem to be faster with StarRocks than with other OLAP databases like ClickHouse, Druid, or Pinot? And how can it deliver fast responses even when data sits on cold storage like S3?
This article covers their answers, the architectural innovations behind StarRocks (colocated joins, caching, cost-based optimizer), and the tradeoffs you should know before evaluating it for your own analytics needs.
Introduction
The modern analytics challenge is to serve queries fast while having data on a data lake on S3, CloudFlare R2 or other places. Usually, the advantages of data lakes (storing data easily without much care about synchronizing database schemas among tables or validating bad rows) result in the opposite of fast queries. This is acceptable if the data is for internal teams or non-critical data. But customers, or also business and domain experts, usually don’t want to wait minutes for a database query result, only to then need to add another filter or column and wait another few minutes.
This workflow is even less efficient with AI agents when they initially autonomously query and narrow down the domain for you. If these queries are slow, the interaction with an agent or chatbot will be even slower.
Enter StarRocks, capable of querying lakehouses - Iceberg, Delta Lake, Hudi, and Hive - in place, without moving data. That’s the pitch. Let’s see how that works.
What is StarRocks?
But first, what is StarRocks? The definition and short version from their docs:
StarRocks is a next-gen, high-performance analytical data warehouse that enables real-time, multi-dimensional, and highly concurrent data analysis.
StarRocks has an MPP architecture and is equipped with a fully vectorized execution engine, a columnar storage engine that supports real-time updates, and is powered by a rich set of features including a fully-customized cost-based optimizer (CBO), intelligent materialized view and more.
StarRocks supports real-time and batch data ingestion from a variety of data sources. It also allows you to directly analyze data stored in data lakes with zero data migration.
StarRocks started as a fork of Apache Doris, but claims to have rewritten 90% of its code since then, mainly to improve performance, stability, usability, etc.
In the past three years, the StarRocks team has replaced the query optimizer with a brand new Cost Based Optimizer to eliminate de-normalization, implemented a Vectorized Query Engine to improve query performance, designed a Primary Key Data Model to better handle real-time analytics scenarios, released Intelligent Materialized Views to simplify data pipelines, and rolled out many other breakthroughs.
Is it a Real-Time Analytics Database, OLAP, Data Warehouse?
StarRocks is also an OLAP system with fast sub-second response times, focusing solely on analytics use cases, not transactional processing. But StarRocks is more than that, as it supports joins, so the terms lakehouse architecture and data warehouse come into play, potentially suiting BI use cases better.
StarRocks implements and provides the capabilities of the MySQL protocol, and with its intelligent materialized views and a newly designed cost-based optimizer (CBO) built-in, it’s a powerful tool that should save you a lot of engineering time.
StarRocks promises one system that can power multiple analytical scenarios, reducing system complexity with Frontend Engine (FE) and Backend Engine (BE) nodes.
Who is Using StarRocks?
There are some big names, some of which we will interview after this chapter. The biggest are Pinterest, Coinbase, Naver, Fresha, Lenovo, Expedia, Trip.com and many more.

Why StarRocks?
So besides other real-time and OLAP databases such as ClickHouse, Pinot, and Druid, when do you choose StarRocks? What are the use cases?
First, let’s see what real StarRocks users that I have interviewed say, before we analyze the technology decisions and techniques that make StarRocks a valid option.
A Simplified Cluster Topology with Support for Fast, Distributed Joins
Key selling points are a simpler architecture, native fast distributed joins, intelligent Materialized Views that can refresh complex joins, and federation as a fast compute engine on top of data lakes and lakehouses with data on object storage.
We’ll hear from Coinbase, Pinterest, and Fresha themselves about why they use it. And we’ll go into joins, colocation, and caching mechanisms later.
But before that, let’s understand the general architecture with two node types, Backend Engines (BE) and Frontend Engines (FE), and why it’s perceived as simpler than others. The backend nodes can be both BEs and CNs (Compute Nodes). The backend nodes support two storage variants: one with local storage in the BE nodes and one with external storage such as S3/HDFS.
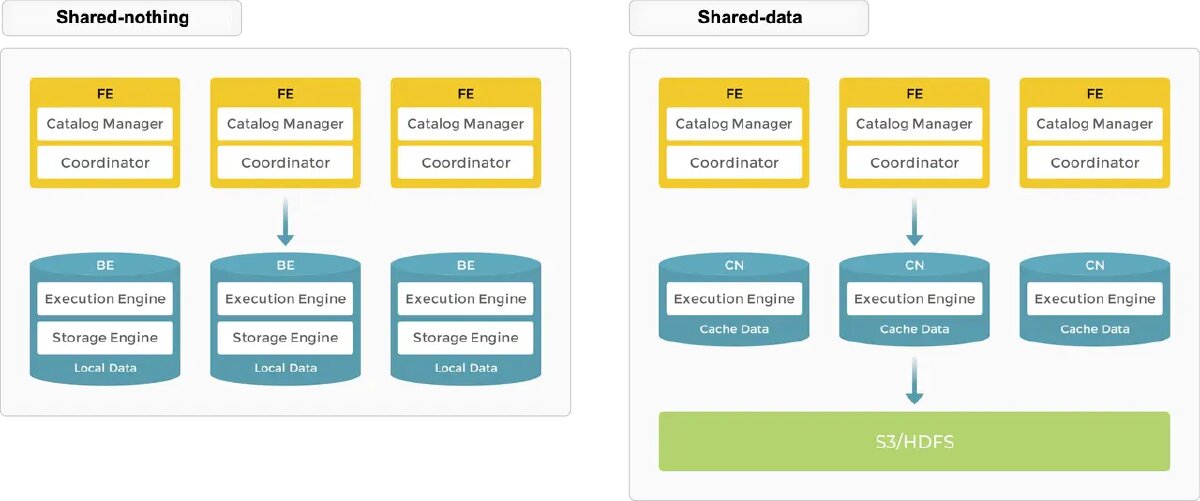
In the shared-nothing architecture, each BE stores a portion of the data on its local storage, and with shared-data, all data is on object storage or HDFS and each CN has only cache on local storage. The default is shared-nothing, meaning direct access to local data on the BE node, but the future is Shared-Data mode to be more cloud-native and reading directly off object store. The convenient thing is that you choose where the data is stored based on your needs.
Keep this in mind while we go through more of the interviews and pros and cons. There are more details in the “StarRocks Technology Decisions” chapter, but let’s first dive into the valuable insights from actual users and companies who explicitly chose this architecture, and why they did so.
Why Coinbase Chose StarRocks
In this part, Eric Sun, Head of Data Platform + Datastores at Coinbase, long-time LinkedIn Manager and experienced with data systems, gave me the pleasure of interviewing him and learning from his expertise. Below are his answers to questions regarding StarRocks at Coinbase, and anecdotes from his personal past.
Coinbase is the largest cryptocurrency exchange in America with over 100 million users and 200 cryptocurrencies. This means they process billions of transactions daily, even more so in short specific periods when the market is active and everyone wants to sell or buy.
The Origin Story for StarRocks at Coinbase
That’s why they started using StarRocks. Originally, 90% of the workloads were on Snowflake, but they needed a faster Operational Data Store (ODS) engine for crypto data services.
Other solutions such as TiDB were tested, but it was too disruptive to bring another transaction processing database into the company. Compared to Pinot, ClickHouse, and Druid, they ultimately chose StarRocks because of these strengths:
- Ingest with light transformation ⇨ pre-aggregate ⇨ analytics lifecycle is still too long/slow for other DWHs like Snowflake and Databricks
- Query performance for ad-hoc and online services requires pre-aggregated, pre-warmed, and pre-cached engines like StarRocks, Doris, Trino, or ClickHouse. Basically balancing both fast data ingestion and join capability, but also near real-time data serving.
- Costs of Snowflake and Databricks are both too high for the use case
And they quickly expanded StarRocks to use for trade/exchange data, event/clickstream, and as a Facebook Scuba alternative.
The JOIN Question
A key and distinctive advantage that StarRocks seems to have over its competitors is the ability to JOIN. Almost like a data warehouse, but with the speed of an OLAP database. I asked Eric how they use joins and if the feature lives up to its promises.
The question that interested me most was: “Can you join and perform simple ETL without persisting data in an intermediate step (like a data mart)? Is that all done automatically with StarRocks? And if so, how can this be fast enough?”
Because you can’t overcome the laws of physics, reading from S3 is just slow. He said the two key techniques are hash-distributed partition + colocation for multiple big tables to join with minimal overhead. He says “this is nothing new, but most other engines, including Snowflake, Databricks, and ClickHouse, have not incorporated these two simple-yet-effective traits”.
He continued with “S3 is slow, so frequently queried data chunks must be automatically cached to the BE (backend) nodes of StarRocks (after the warm-up queries) in the ‘shared-data’ mode”.
Further, I asked him: “But how do you model the data flow then? How does StarRocks fit the picture, are you doing any ETL before landing in StarRocks?”
He surprised me with data modeling still being the key:
Transactional Processing (OLTP or relational) data models in most cases are not a good fit for StarRocks or ClickHouse. But if the join/foreign keys are clearly defined in the data models, StarRocks can leverage Colocate Join to reduce pre-join via ETL.
However, pre-join can always bring visible benefits to query performance and data quality. The point here is about how much percentage data models can be efficiently served via StarRocks without streaming joins in Flink/Spark which requires highly-skilled engineers.
He continues with denormalization and colocation by dimension:
Event data are typically denormalized to some extent, so we typically just need to colocate the big event table with the big User/Customer/Product dimension table via theUSER_ID/CUSTOMER_ID/PRODUCT_ID
We will explore colocate joins in a bit, as this seems to be a key part of the speed for joins. Also, the distinction between when to stream and when to use StarRocks is super helpful and shows again that almost all good designs come down to good data architecture and modeling your data flow.
On top of that, Eric mentioned that “query planning and data modeling is the key to the success of their project”. For example, they use Kafka as a Sink and land data before going into StarRocks as one modeling choice for certain data.
Colocated JOINS: How They Work
Interestingly, colocating dimensions with the large fact tables is a noteworthy approach. Let’s quickly explore how these colocated joins work in detail to understand the importance of this, before we get back to the interview.
Colocate Join lets equi-joins run locally by ensuring tables share the same bucketing key, bucket count, and replica placement so corresponding bucket copies reside on the same backend nodes, avoiding network shuffle or broadcast overhead.
Tables that should join together are organized into a Colocation Group (CG) with the same schema (Colocation Group Schema (CGS)), consisting of these three properties that must be the same for all tables:
- Same bucketing key (type and order). e.g., both tables use
customer_id INT - Same number of buckets. e.g., both have 8 buckets
- Same replica count. e.g., both have 3 replicas
This guarantees that rows with the same customer_id always land on the same node, making joins local.
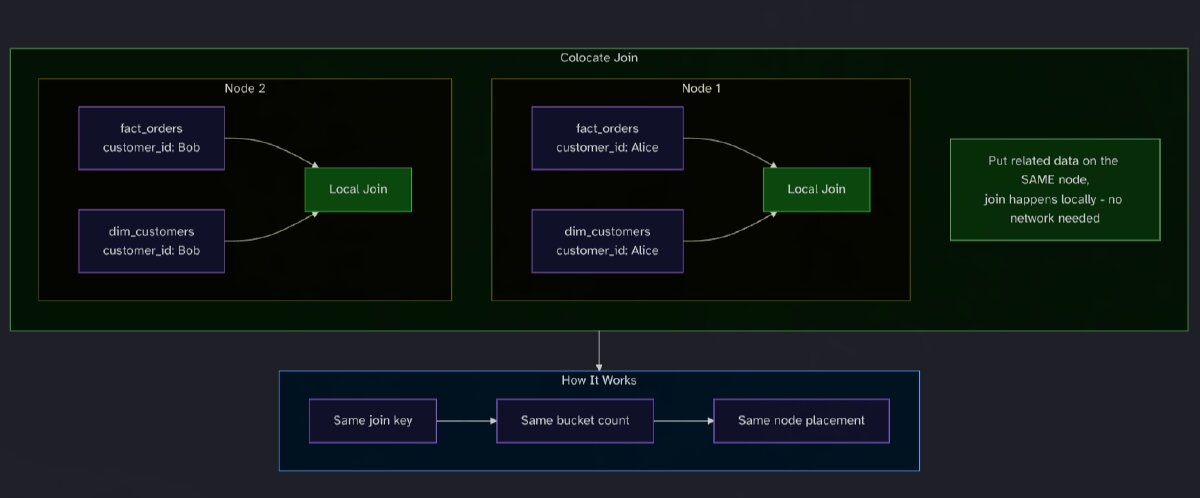
There’s much more. Check out the docs on Colocated joins and Schema Tuning Recipes. But this also shows that there’s a lot of planning involved in how you model your data, as these settings need to be consistent across tables and optimized for your use case and data.
Trade-offs: Key for Partitions
There are always tradeoffs. As seen with the colocation and schema groups, you need to define what to colocate on. You need to know your data well.
It’s the same as we always did in our work, deciding what to partition on, but here it’s done more holistically across nodes and tables. It’s a tradeoff and a choice which columns you do exactly that for.
For example, Coinbase with its Bitcoin data has distinct addresses and dates, so you could either partition by range on such high-cardinality addresses or by blockchain timestamp, but you can’t use both. You need to decide.
On distribution key tradeoffs, Eric says:
You can only optimize for one of them and leverage the index for the other one. That’s a trade-off you have to do.
This also fits into how you model the data so you don’t need to join, or when you do, you can join efficiently. StarRocks excels at joins using primary keys or unique keys.
For Coinbase’s blockchain use case with high-cardinality address columns, Eric and Xinyu recommend:
- Partition by timestamp (monthly) rather than by address, as high cardinality makes address-based partitioning operationally unscalable.
- Distribute by only one address column (from OR to, not both). If you distribute by both, queries must use AND predicates, which rarely match actual query patterns.
- Use ORDER BY on the distribution column to avoid needing bitmap indexes on that column.
- Create a secondary lean table optimized for the other address column, then join back using compound keys (transaction ID + timestamp + block hash).
Struggles with StarRocks
When asked what they lost or struggled with when switching to StarRocks, Eric said that the community is much smaller than ClickHouse’s, for example. A well-known community and perception in the US is important, as most people in the Bay Area and Seattle area have still never heard about StarRocks.
Compared to ClickHouse, which is buying analytical solutions and trying to be a cohesive software stack, StarRocks seems to take a simpler and slower approach, he comments.
He also missed the stability compared to Snowflake, as new releases sometimes introduce dozens of small errors in certain areas such as deployment, system metadata, and elastic compute. But overall, it is mainly popularity and acceptance from the user community, because “people are more willing to try and learn the technology that they have heard about or their friends can mention”, he says.
Forward-Looking: Lakehouse Architectures and Benchmarks
When asked about using StarRocks with Iceberg/Lakehouse solutions and loading data directly, Eric said: “Both: hot and recent data (2 weeks ~ 3 months) are stored in StarRocks native layout on S3, such as partition, index, bucketing, colocation, …, while the cold historical data are federated from Iceberg/Delta to share the same data partitions from Lakehouse. Iceberg can’t deliver the performance compared with the native storage format”.
In terms of comparison and benchmarks, Eric says that StarRocks significantly outperformed ClickHouse in their TPC-H 1TB benchmarks. ClickHouse failed 12 of 22 queries due to out-of-memory errors, particularly on join-heavy queries. The data was 10 blockchains with 300+ tables and 573 billion rows.
But the competition is still ongoing, he says: “Simply put, StarRocks naturally fits much better for multi-table join scenarios especially for e-commerce and finance sectors. And ClickHouse has better out-of-box templates for observability use cases”.
He continues that ClickHouse is harder to maintain, as there are so many knobs and tweaks, whereas StarRocks on average is much simpler for the engineering team to understand and learn, and more manageable.
When asked what they can learn from each other, Eric said this:
- StarRocks should learn from ClickHouse: Memory Table, Integration / Connector with other partners, and rich complex/advanced UDF/UDAF
- ClickHouse should learn from StarRocks: Sophisticated cost-based optimizer (CBO), multi-table Materialized View, primary key table optimization for DML, Concurrent Queries and Join Join Join
Why Fresha Switched to StarRocks?
The second interview with Anton Borisov, an experienced Principal Data Architect at Fresha and a heavy user of StarRocks who is building their own tooling on top of it, gives us more valuable insights. Anton has a strong background with relational databases, specifically Postgres, and has worked with distributed OLAP systems. Fresha is the world’s leading marketplace platform for the beauty, wellness, and self-care industry, trusted by millions of consumers and businesses worldwide.
First, we talked about why they switched, and it was the same pattern as with Coinbase. Customer-facing analytics built on top of dbt materialization and batched into Snowflake got too slow (every 20 minutes).
Anton was a big ClickHouse user and wanted to use it first. But then they discovered StarRocks and found that the joins would simplify their architecture. Especially with dbt where they ended up with lots of different layers, CTEs, joins, etc. So with StarRocks, they threw the same SQL at it and got a sense of how it performed and how feasible it was. That was their first baseline of what’s possible and how fast. They achieved that rather quickly and could optimize on top of it. Whereas with ClickHouse it was much harder to set up a first working baseline to then iterate and improve on.
As the first baseline was 4 seconds with lots of joins, it was a great start from which they could tweak colocation and optimize data flow.
Anton told me that Fresha uses two pipelines or ways of ingestion into StarRocks:
- Streaming data that is slightly pre-aggregated with Flink and then ingested directly into StarRocks. StarRocks then handles the optimal storage with CN (Compute Nodes), which are stateless and fetch data from S3 in shared-data mode. Then you have cache in memory and disk. You could also use Kafka Connect, Debezium, and many other ways to ingest.
- Data from S3. Here the workflow is
Snowflake -> Spark joins and export to Iceberg -> StarRocks- Important to note: Spark gave them the best option to add as much metadata as possible, like Apache Puffins and general Iceberg metadata, for StarRocks to quickly read from, even if not in hot storage.
- This approach is done on a batch schedule, usually once a day. Also interestingly, they might duplicate certain datasets and store them in different sorting orders (e.g., one on dimension customer, one on dimension region), just to have StarRocks optimize reading on cold and cheaper S3 storage for different dashboards. You pay extra for S3, but you can avoid expensive hot cache if you want. You can still let StarRocks load some of it into local cache to speed things up, say if there’s an event coming up.
- This architecture makes it flexible without having to change data pipelines.
- Fresha treats Iceberg tables as mostly immutable: data is ingested append-only, and they don’t continuously apply row-level corrections. Instead, they accumulate corrections and periodically re-ingest/merge them back into Iceberg for the workloads that need corrected history. The target model is that older (non-operational) data remains stable, with only controlled correction cycles rather than ongoing mutations.
The way it works is that data from Flink lands in RAM first, then gets offloaded into cache. There is an option to specify the cache-to-memory ratio, but you can’t control it directly, so you need to tweak the workload. They use the shared-data mode for this. Remember the above image about the architecture overview.
Regarding joins, Anton said that they just work as you’d expect from a data warehouse. The speed heavily depends on how much “money” you invest, meaning how many CN nodes you scale up when reading from S3, for example. And because CN nodes in the shared-data architecture are stateless, it’s easy to scale up more nodes. A great detail Anton shared: these CN nodes do RPC (bRPC to be specific) calls with each other to communicate.
You can also use Materialized Views for Joins and Ingestions, but they do most in Flink or Spark.
How to Handle Data Updates
Data is updated with a continuous streaming job like Flink. StarRocks has a compaction job that optimizes the data that has been updated. It’s an internal process where you configure some limits and times for it. Colocation, though, is handled a bit differently, either when you declare the table during ingestion or when you change the table definition with DDL. Then the engine distributes tablets to the correct nodes so they are physically together.
What if you need to backfill new data? Backfilling is the same as updating data. Either you set up a Flink job that ingests older missing data slowly, one batch after another. Or you do an Iceberg export that you can load from. Fresha uses StarRocks pipes for this. Either way works.
Schema changes are a bit different from other systems. You need to stop ingestion from Flink, change the schema and dataset coming from the Flink job, change the DDL statement for your table definition in StarRocks, and then restart the pipeline. Only then do you see the new column.
Tradeoffs
Anton says these are always the same: you can have super-fast real-time ingestion, but then it’s more expensive. Or you have a little longer latency until everything is ingested, but at a lower cost.
Most important is the query speed, where their baseline is under 1 second (web analytics p95 is ~100ms) across all queries. For the business user, it should not matter whether joins are happening under the hood, whether data is stored in S3 with Iceberg, or whether it is coming directly from the StarRocks internal format.
If data is fully cold and on S3, StarRocks still manages 3-5 seconds of query latency based on extensive Puffin and Iceberg metadata sorted in the right order, Anton says.
Check out also the Fresha Data Engineering Blog for many more insights from the team about best practices around StarRocks and more. Or check out their Northstar utility for StarRocks, or the recent video about StarRocks at Fresha.
Pinterest: From Druid to StarRocks
Perhaps the biggest company that uses StarRocks is Pinterest. I wasn’t able to reach anyone to interview, but there’s a great article online at Delivering Faster Analytics. Let’s analyze it.
Pinterest migrated from Apache Druid to StarRocks to power their Partner Insights tool, which provides real-time analytics dashboards to advertisers tracking ad performance across 500+ million monthly active users. After the migration, they reduced p90 query latency by 50% while using only 32% of their previous infrastructure. This is roughly a 3x improvement in cost-performance efficiency.
Their setup runs on 70 backend engines and 11 frontend nodes. The MySQL compatibility allowed easy integration with existing tools, and StarRocks’ native ingestion eliminated the need for heavy MapReduce jobs in their data pipeline.
Additionally, there are some interesting comments on Reddit related to this article. People using Druid and ClickHouse stated that:
Both can handle multi-petabyte deployments the product seems to cover gaps within both architectures (Druid has an extremely heavy/complex footprint with limited join capabilities and is fairly costly to run). While Clickhouse can handle multi-petabyte volumes, certain design choices architecturally prevent it from auto rebalancing data which is critical at larger scale data volumes.
He would use StarRocks “largely because user requirements are only getting more complex at our company and architecturally/capability-wise StarRocks seems to be really the only OS solution that actually has near-direct compatibility with the MySQL protocol, materialized views and supports both real-time + batch loads, upserts. There is just a lot you can enable with just those four capabilities.”
Index Exchange & Others
It sounds similar from Ivan Torres, Staff Engineer at Index Exchange, who says:
I use StarRocks open source on K8s and benchmarked it against Druid. I also used ClickHouse before. For real time data they all come pretty close, some optimizations of each database work better for specific use cases, but you can achieve pretty similar numbers with the three of them.
What made me go to StarRocks is that it is a lot more versatile. It also does pretty good ad-hoc analytics and integrates with external catalogs like Iceberg for reading external tables. You can also have full separation of storage and compute and achieve good performance with disk caching.
He goes on to compare: in “Druid, joining tables ad-hoc is pretty much impossible”. And in ClickHouse, the “integration with external tables is not yet there,” he said.
But there are also some limitations. I had someone at a large payroll company reach out. They found it quite difficult to tune at scale and decided to migrate away from it. Difficult to manage, as in a full-time job, but powerful. They liked the StarRocks model, but didn’t have the engineering resources to maintain and tune it beyond what they could support at the time. They split workloads between ClickHouse and Snowflake based on use case.
As always, it’s a tradeoff. You need the right system for the right use case and the right engineering skills to manage it yourself, or just use the hosted version of each platform.
Common Patterns Across Adopters
Recapping before we go into the technical deep dive. Common patterns and use cases I found while interviewing the above companies and people:
- Joins as the really powerful part: Everyone mentioned the capabilities of joins as why they chose StarRocks over ClickHouse, Druid, or Pinot. Not just that joins work, but that they work without heavy pre-denormalization in Flink/Spark first.
- Faster time-to-baseline: Getting a working baseline to iterate from, compared to more complex setups, saving costs as the engineering team understands it faster.
- Use it when you want to speed up Snowflake or directly read from Iceberg tables: Limits are hit when customer-facing apps need sub-second query-response times.
- Hybrid hot/cold as the deployment pattern: Both Coinbase and Fresha run streaming into StarRocks for recent data while federating over Iceberg for cold historical data. StarRocks becomes the unified query layer across both.
Besides all the advantages, it’s clear that good data modeling is still required at every step. Colocated joins require upfront planning on how to set the same bucket key, count, and replica placement across tables. Basically, the partition key not only for a single table, but across a set of tables for best performance. Data flow and schema design should get a lot of love, as always in my opinion.
Now that we have heard a lot from actual users, let’s go into the details and analyze the parts we haven’t covered yet under the hood to see how the speed is possible and understand the architecture decisions that have been made.
StarRocks Technology Decisions and Architecture
Before we end, let’s look at some more of the interesting architectural decisions StarRocks makes.
Caching: The Alternative to Ingestion
In shared-data mode, data sits on slower object storage. StarRocks mitigates this with a multi-tier cache: memory -> local disk -> remote storage. Queries hit hot cache first, and cold data gets prefetched based on optimized strategies.
This means you don’t need ETL jobs to “load” data into StarRocks. You create an Iceberg catalog, point it at your existing tables, and queries automatically warm the cache over time. For predictable workloads, use the cache warmup command to proactively load specific tables before users hit them.
How it works under the hood: When querying Iceberg on S3, StarRocks splits remote Parquet/ORC files into fixed-size blocks (default 1MB) and caches them locally. Each block gets a unique key based on filename, modification time, and block ID. The first query fetches from remote storage, and subsequent queries read from local NVMe/SSD. Cached data persists across restarts.
On top of block cache, an in-memory page cache stores decompressed data pages and metadata. Hot data lives in memory, warm data on disk, cold data stays on S3. StarRocks also caches Iceberg metadata (manifests, schemas) to avoid catalog round-trips on every query.
The tradeoff is that the first queries on cold data still hit remote storage, but once warmed, performance matches native tables.
Real-Time Updates Without the Merge Overhead
Beyond caching, StarRocks handles real-time data updates efficiently through its columnar storage engine. Data of the same type is stored contiguously, enabling better compression and reduced I/O as you query only the columns you need.
But what makes it interesting for real-time analytics is how it handles updates. Traditional OLAP systems use different strategies:
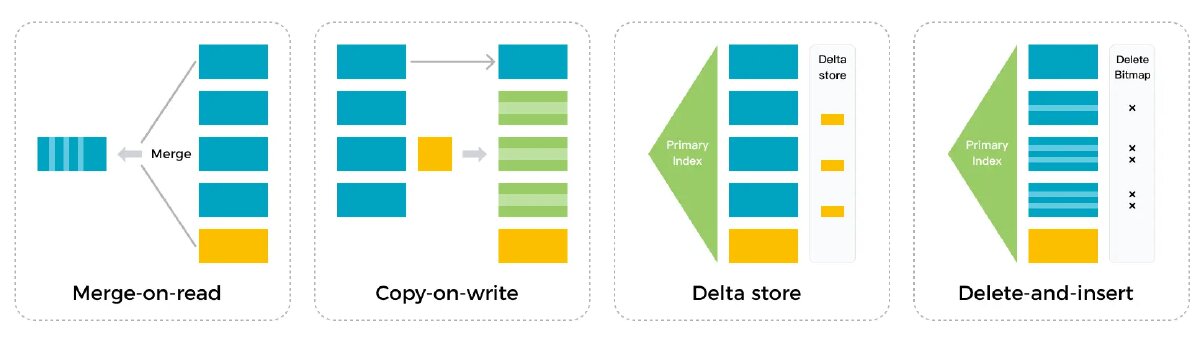
StarRocks uses the delete-and-insert pattern. Instead of merge-on-read (which pays the merge cost at query time) or copy-on-write (which rewrites entire files on updates), StarRocks maintains a primary key index with delete bitmaps. Updates mark old rows as deleted and insert new ones. No expensive sort-merge at read time. This means sub-second data visibility for upserts while keeping query latency predictable, even on large update volumes.
The storage engine guarantees ACID for each ingestion operation: transactions either fully succeed or fail, with isolation between concurrent loads.
Cost-Based Optimizer (CBO): Avoiding Joins Without Upfront Denormalization?
On-the-fly joins aren’t typically a strength of OLAP databases, but they are one of StarRocks’ strengths, as we discussed. If your execution engine is fast enough, you avoid pre-building denormalized data marts, saving storage costs and ETL complexity.
Why are StarRocks joins fast?
The cost-based optimizer navigates the exponential search space of join plans, automatically transforms expensive join types into cheaper ones, and aggressively pushes predicates down before data reaches the join.
The optimizer leverages rich statistics including histograms for skewed data distributions and multi-column joint statistics to produce accurate cardinality estimates that guide join ordering and execution strategy selection.
When you still want denormalization: For high-concurrency scenarios serving hundreds of simultaneous users, pre-aggregated views still win. The difference is you start with normalized data, query it directly, and selectively add materialized views where needed. Fresha, NAVER, and others use this feature, e.g., NAVER achieved 6x speedups on specific high-traffic queries.
Intelligent Materialized Views
StarRocks reads Iceberg/Hive tables in-place without copying data. Its vectorized engine processes Parquet/ORC directly, and the only overhead is metadata lookup. No transformation is needed.
The query flow:
- Frontend receives query → queries catalog for table metadata
- Extracts file paths from Iceberg manifests (no data read yet)
- Distributes file locations to Backend nodes
- Backend opens Parquet/ORC directly from S3, applies predicate pushdown
- Reads only required columns (late materialization)
On top of this, StarRocks’ intelligent materialized views auto-refresh based on base table changes and are selected automatically at query time. The optimizer rewrites queries to use MVs when beneficial. No manual intervention is needed.
This enables a layered approach to data modeling without traditional ETL pipelines:
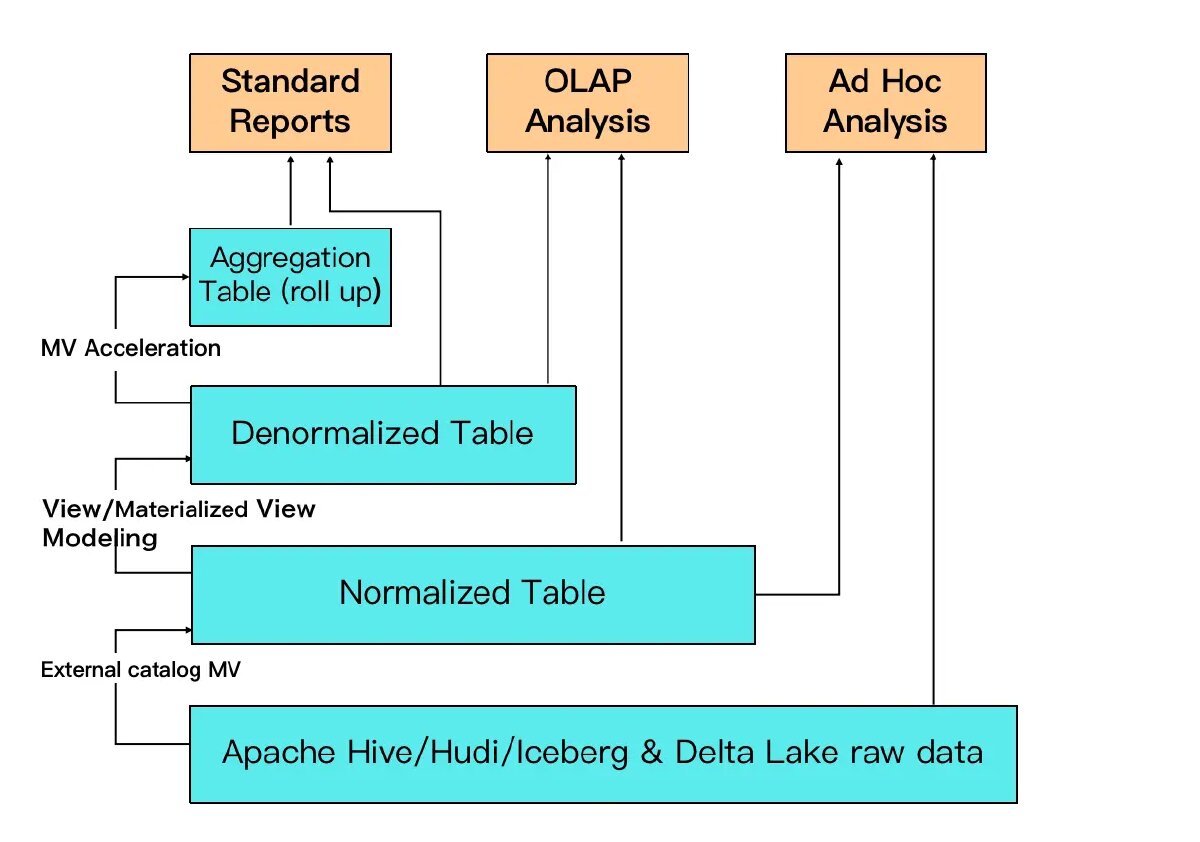
Starting from the bottom: raw data sits in your data lake (Iceberg, Hudi, Delta Lake, Hive). An external catalog MV can transform this into normalized tables, still queryable for ad-hoc analysis and OLAP workloads. From there, async MVs can create denormalized tables for faster OLAP queries. For high-concurrency standard reports, aggregation MVs (roll-ups) pre-compute the heavy lifting.
The key insight is that you don’t build all these layers upfront. You start with normalized data, query it directly, and see if it’s fast enough. Then be selective and add MVs where you see bottlenecks. You preserve the single source of truth in Iceberg while progressively optimizing hot paths.
To repeat, at a high level, StarRocks achieves its performance through four architectural decisions: Colocate Join for zero network overhead on co-located data, delete-and-insert for O(1) updates instead of merge-on-read, direct Parquet/ORC reading with no ingestion transformation, and SIMD Vectorization for faster filtering/aggregation on Parquet computation to determine whether data rows are empty.
Conclusion: Is StarRocks Too Good to Be True?
So when should you actually choose StarRocks? After interviewing Coinbase, Fresha, and digging into Pinterest’s migration, the pattern is clear. Choose StarRocks when joins are central to your analytics.
ClickHouse excels at single-table aggregations and observability. But if you’re constantly pre-denormalizing in Flink or Spark just to avoid joins, StarRocks lets you skip that pain.
Here’s my mental model as of now:
Again, choose StarRocks when you hit cloud DWH speed limits for customer-facing analytics, need real-time analytics (<50ms), have frequent updates/deletes, want to query Iceberg/Hive directly, need complex joins, or want MVs on external tables.
But advanced features don’t come without tradeoffs. You have to choose a partition key across colocated tables, but you can only optimize for one of them. Overall, good data modeling still matters. And if one of them is your main use case, it’s always best to create a Proof of Concept where you test and compare the differences.
If you’re looking for a real-time BI and dashboarding tool designed to benefit from StarRocks’ real-time query performance, check out Rill and the recently released native StarRocks connector. With it, you can connect directly to your StarRocks instance and query data in real time without first ingesting it into Rill, expanding Rill’s support alongside ClickHouse, Druid, and Pinot. You simply specify StarRocks in their source YAML and off you go. Check out the docs for more information. All open-source if you want. Cloud-ready if you need.
Special thanks to Eric and Anton, who took the time to answer my questions and helped me learn a lot about how StarRocks works. Follow them on LinkedIn and subscribe to their blogs and posts.
References
- Bajaj, K., Luo, Z., Yang, Y., Barai, S., & Hu, M.-M. (2024, July 31).
Delivering Faster Analytics at Pinterest. Pinterest Engineering Blog.
Link — Describes Pinterest’s migration from Druid to StarRocks for their
Partner Insights platform, achieving 50% p90 latency reduction at
32% of the previous instance count, resulting in a 3x cost-performance
improvement. - Vuong, H., & Cao, H. N. (2025, March 6). Building a Spark observability
product with StarRocks: Real-time and historical performance analysis.
Grab Tech Blog.
Link — Describes Grab’s “Iris” Spark observability platform redesign, migrating
from a TIG stack (Telegraf/InfluxDB/Grafana) to a StarRocks-centered
architecture to unify real-time + historical analysis and simplify
ingestion/visualization. - Shekhawat, V., & Andrews, M. (n.d.). From BigQuery to Lakehouse: How
We Built a Petabyte-Scale Data Analytics Platform – Part 1. TRM Blog.
Link — Explains TRM Labs’ move from BigQuery + distributed Postgres toward a
lakehouse architecture, selecting Apache Iceberg for table format and
StarRocks as the query engine for low-latency, high-concurrency
user-facing analytics. - Event Recap, StarRocks Singapore Meetup #2 @Shopee. (n.d.). 知乎专栏
(Zhihu).
Link — Event recap for a StarRocks community meetup hosted at Shopee’s
Singapore office, describing talks and themes around customer-facing
analytics use cases. - Shen, S., & Sun, E. (2024, June). Data Warehouse Performance on the Data Lakehouse [Lightning Talk]. Data+AI Summit 2024, Databricks. Link — A joint talk by CelerData and Coinbase presenting how StarRocks delivers data warehouse-level query performance directly on the data lakehouse.
.jpg)
.svg)

.jpg)

Ready for faster dashboards?
Try for free today.