Build fast agentic analytics with Claude Code and Rill
Learn more
Product
Overview
Pricing
Solutions
Programmatic advertising
Audio advertising
Infrastructure monitoring
Product analytics
IoT & logistics
Resources
Documentation
Example demos
Case studies
Release notes
Blog
Events
Talks
About us
Team
Careers
Contact us
Log in
Get started
Go to Media Kit
Blog
Featured Posts
Nishant Bangarwa
•
April 8, 2026
min
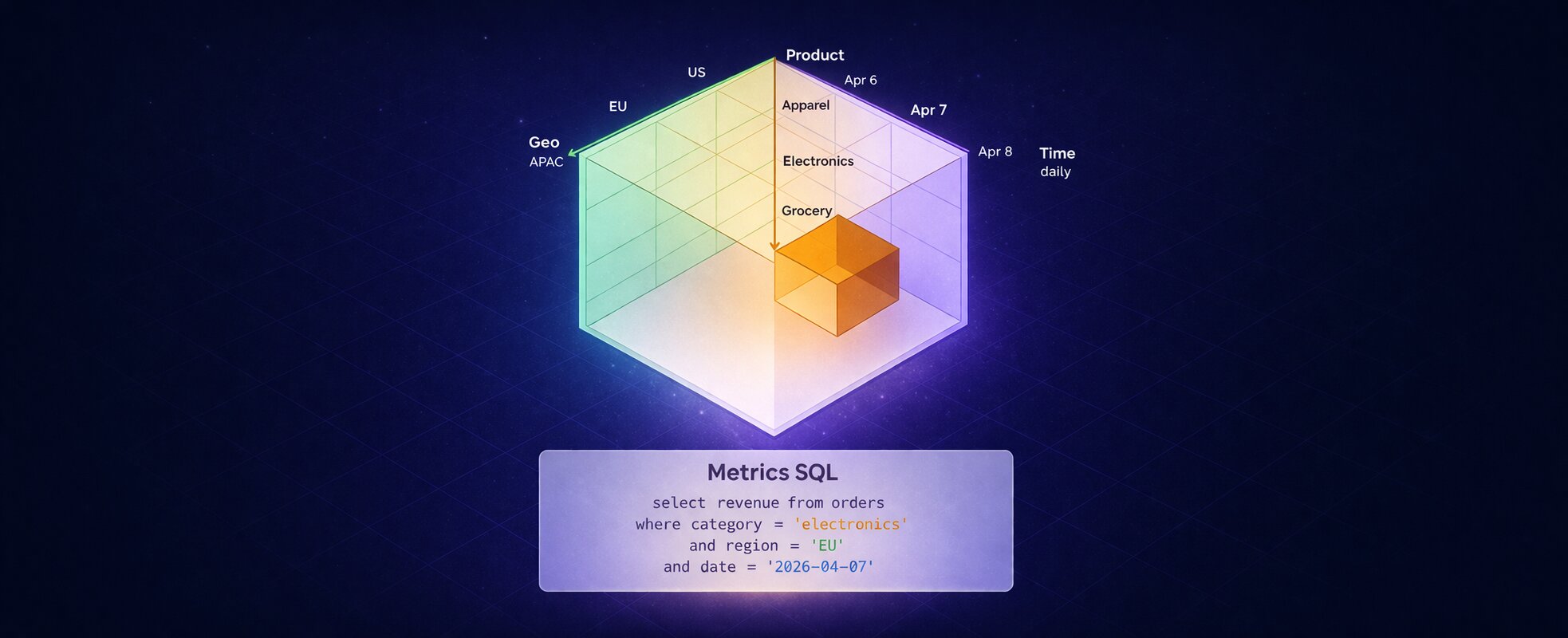
Introducing Metrics SQL: A SQL-based semantic layer for humans and agents
Product
Nishant Bangarwa
•
April 20, 2026
min
Feed the beast: Building a data stack that agents love
Agent analysts demands new architectures focused on semantics, speed, and scale.
Product
Simon Späti
•
April 14, 2026
min
AI Reveals Why BI Still Matters (Hint: It’s Not Dashboards)
Deep Dives
CATEGORIES
Data-Driven Leader Series
Company
Product
Deep Dives
Use Cases
Partners
Data Talks on the Rocks
Reset
Sort by:
Date
Date
Author name (A-Z)
Alphabet (A-Z)
Nishant Bangarwa
•
April 20, 2026
min
Feed the beast: Building a data stack that agents love
Agent analysts demands new architectures focused on semantics, speed, and scale.
Product
Jon Walls
•
April 20, 2026
min
Video: Building Fast Agentic Analytics with Google Antigravity and Rill
Product
Simon Späti
•
April 14, 2026
min
AI Reveals Why BI Still Matters (Hint: It’s Not Dashboards)
Deep Dives
Michael Driscoll
•
April 1, 2026
min
How the Weights & Biases Cofounder Created One of AI's Defining Exits
Data Talks on the Rocks - Lukas Biewald
Data Talks on the Rocks
Jon Walls
•
March 20, 2026
min
Video: Building Fast Agentic Analytics with Cursor and Rill
Product
Simon Späti
•
March 9, 2026
min
Building an Agent-Friendly, Local-First Analytics Stack with MotherDuck and Rill
Deep Dives
Jon Walls
•
March 5, 2026
min
Video: Building Fast Agentic Analytics with Claude Code and Rill
Product
Simon Späti
•
February 11, 2026
min
Why Coinbase and Pinterest Chose StarRocks: Lakehouse-Native Design and Fast Joins at Terabyte Scale
A technical deep dive into StarRocks, with engineer interviews from Coinbase and Fresha.
Deep Dives
Michael Driscoll
•
February 10, 2026
min
Python Was Built for Humans. AI Just Changed Everything.
Data Talks on the Rocks - Wes McKinney
Data Talks on the Rocks
Michael Driscoll
•
January 20, 2026
min
How ClickHouse became one of the fastest-growing databases in the world
Data Talks on the Rocks - Alexey Milovidov
Data Talks on the Rocks
Michael Driscoll
•
January 7, 2026
min
The Semantic Layer Problem Nobody Wants to Talk About
Data Talks on the Rocks - Lloyd Tabb
Data Talks on the Rocks
Alex Thor
•
December 19, 2025
min
Rill in Review: Top Features That Shaped 2025
Product
Michael Driscoll
•
December 16, 2025
min
DuckDB Won By Refusing to Scale Out
Data Talks on the Rocks - Hannes Mühleisen
Data Talks on the Rocks
Simon Späti
•
December 4, 2025
min
dlt+ClickHouse+Rill: Multi-Cloud Cost Analytics, Cloud-Ready
FinOps Made Easy: A Starter Repo to Oversee Cloud Costs from Different Hyperscalers.
Deep Dives
Michael Driscoll
•
December 2, 2025
min
The Modern Data Stack Is Over. Here’s What’s Next.
Data Talks on the Rocks - Matthaus Krzykowski
Data Talks on the Rocks
Simon Späti
•
November 21, 2025
min
Multi-Cloud Cost Analytics: From Cost-Export to Parquet to Rill
An Open-Source Framework for Multi-Cloud Cost Visibility
Deep Dives
Michael Driscoll
•
November 18, 2025
min
The Great Reset: How AI Is Forcing Data Teams Back to Zero
Data Talks on the Rocks - Joe Reis
Data Talks on the Rocks
Simon Späti
•
October 17, 2025
min
Data Modeling for the Agentic Era: Semantics, Speed, and Stewardship
Three Pillars of Conversational Analytics
Deep Dives
Simon Späti
•
September 10, 2025
min
Data Modeling Guide for Real-Time Analytics with ClickHouse
Deep Dives
Michael Driscoll
•
September 8, 2025
min
Data-Driven Leader Series - Episode 2 - Digital Turbine
Data-Driven Leader Series
Simon Späti
•
July 10, 2025
min
Data Engineering Postcard Series
Summer Edition ☀️ Quick insights for your beach reading
Partners
Jon Walls
•
June 25, 2025
min
Top 10 tips for using Claude Desktop with Rill Data
Use Cases
Simon Späti
•
June 20, 2025
min
Has Self-Serve BI Finally Arrived Thanks to AI?
How conversational BI and MCP deliver on two decades of promises
Deep Dives
Michael Driscoll
•
June 2, 2025
min
Data-Driven Leader Series - Episode 1 - Disco
Data-Driven Leader Series
Michael Driscoll
•
May 20, 2025
min
Data Talks on the Rocks 8 - ClickHouse, StarTree, MotherDuck, and Tobiko Data
Data Talks on the Rocks
Simon Späti
•
May 17, 2025
min
The Open Table Format Revolution: Why Hyperscalers Are Betting on Managed Iceberg
Deep Dives
Janet Hwu
•
April 22, 2025
min
Introducing Canvas dashboards — a new way to visualize metrics
Product
Simon Späti
•
April 11, 2025
min
What "Shifting Left" Means and Why it Matters for Data Stacks
Deep Dives
Michael Driscoll
•
April 4, 2025
min
Data Talks on the Rocks 7 - Kishore Gopalakrishna, StarTree
Data Talks on the Rocks
Simon Späti
•
March 10, 2025
min
Scaling Beyond Postgres: How to Choose a Real-Time Analytical Database
Deep Dives
Michael Driscoll
•
February 19, 2025
min
Why You Need a SQL-based Metrics Layer
Deep Dives
Simon Späti
•
February 3, 2025
min
Why Pivot Tables Never Die
Deep Dives
Simon Späti
•
December 20, 2024
min
Designing a Declarative Data Stack: From Theory to Practice
Part 3 of 3
Deep Dives
Alex Thor
•
December 12, 2024
min
2024 Product Recap - 5 Top Features
Product
Michael Driscoll
•
December 5, 2024
min
Data Talks on the Rocks 6 - Simon Späti
Data Talks on the Rocks
Simon Späti
•
November 4, 2024
min
BI-as-Code and the New Era of GenBI
Part 2 of 3
Deep Dives
Simon Späti
•
October 16, 2024
min
The Rise of the Declarative Data Stack
Part 1 of 3
Deep Dives
Marianne Jarvis
•
June 13, 2024
min
Video: How Rill powers fast, exploratory dashboards with ClickHouse
This presentation was given at a ClickHouse meetup in San Francisco on June 4, 2024
Partners
Alex Thor
•
May 6, 2024
min
Introducing the new File Explorer
Product
Alex Thor
•
March 18, 2024
min
Introducing the Rill pivot table
Based on the 1991 original hit by Lotus
Product
Nishant Bangarwa
•
February 26, 2024
min
ClickHouse dashboards with Rill: instant, operational BI at scale
"Why not scale up Rill using ClickHouse?"
Partners
Alex Thor
•
December 20, 2023
min
2023 Product Recap - 6 Big Features
Product
Michael Driscoll
•
December 5, 2023
min
Data Talks on the Rocks 2 - Vercel and Tabular
Fireside chat with the founders of Vercel and Tabular
Data Talks on the Rocks
Michael Driscoll
•
October 13, 2023
min
Data Talks on the Rocks 1 - Modal Labs, Pinecone, Ask-Y
Vibrant panel discussion featuring Edo Liberty, Erik Bernhardsson, and Katrin Ribant
Data Talks on the Rocks
Dhiraj Kumar
•
September 14, 2023
min
Lessons Learned in Developing Interactive Time Exploration in Rill Dashboards
Deep Dives
Katie Staveley
•
August 2, 2023
min
Fast DuckDB-Powered Dashboards with Rill and MotherDuck
Partners
Eric Green
•
July 6, 2023
min
Analyze Your GitHub Repository with Rill
Use Cases
Michael Driscoll
•
May 31, 2023
min
Introducing Rill Cloud: The Fastest Path from Data Lake to Dashboard
Rill Cloud public beta now available
Product
Marianne Jarvis
•
May 17, 2023
min
The Journey from Metamarkets to Rill
“It really changes how people interact with data.” - Sr. Director of Analytics at Liftoff
Company
Michael Driscoll
•
April 19, 2023
min
Why We Built Rill with DuckDB
Partners
Michael Driscoll
•
August 4, 2022
min
Why We Raised $12M to Reimagine Business Dashboards
tl;dr Business dashboards are broken, Rill is a tool to fix them.
Company
Marissa Gorlick
•
May 6, 2022
min
Accelerating the Core Analysis Loop
Achieve flow in your work with tools that bring data insights at the speed of conversation.
Deep Dives
Neil Buesing
•
December 22, 2021
min
How to Create Roll-ups in Apache Druid
Use Cases
Neil Buesing
•
December 16, 2021
min
Seeking the Perfect Apache Druid Rollup
Deep Dives
Scott Cohen
•
October 21, 2021
min
Apache Airflow for Orchestration and Monitoring of Apache Druid
Part 2: Observability Logic for High Uptime SLAs
Use Cases
Scott Cohen
•
October 18, 2021
min
Apache Airflow for Orchestration and Monitoring of Apache Druid
Part 1: Technical Integration for Workflow
Use Cases
Neil Buesing
•
October 12, 2021
min
Fast Path to Streaming Data Analysis
Geospatial Tutorial
Deep Dives
Michael Driscoll
•
October 4, 2021
min
The Guide to Apache Druid Architectures
Deep Dives
Adheip Singh
•
October 1, 2021
min
Setting up Apache Druid on Kubernetes in under 30 minutes
Deep Dives
Margie Roginski
•
July 22, 2021
min
Guide: Connect Looker to Druid and explore your data in real time
Deep Dives
Margie Roginski
•
July 6, 2021
min
Guide: Connect Druid to Tableau for sub-second dashboards
Deep Dives
Margie Roginski
•
June 10, 2021
min
How to achieve fast query speed with no DevOps maintenance
Deep Dives
Margie Roginski
•
June 3, 2021
min
Introducing Rill Data’s BigQuery Connector
Partners
Margie Roginski
•
May 27, 2021
min
Druid + Looker? Druid + Tableau? Leverage data interoperability for data visualization
Partners
Margie Roginski
•
May 20, 2021
min
Apache Druid and Rill: better together
Deep Dives
Margie Roginski
•
May 13, 2021
min
When should I use Apache Druid? Try this checklist.
Use Cases
Michael Driscoll
•
May 1, 2021
min
Apache Druid Turns 10: The Untold Origin Story
Company
Michael Driscoll
•
April 22, 2021
min
Operational intelligence and the new frontier of data
Company
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.svg)

.jpg)



